Data structure in DigiKAR
Humanities projects, especially historians, work with large amounts of data from various sources that often need more structure. Ingesting these data into an easy-to-use database that permits complex queries or visualisations is often unattainable. Therefore, we conducted a careful tool review at the beginning of the DigiKAR project to be able to discuss the advantages and challenges of different (open source and proprietary) database systems:
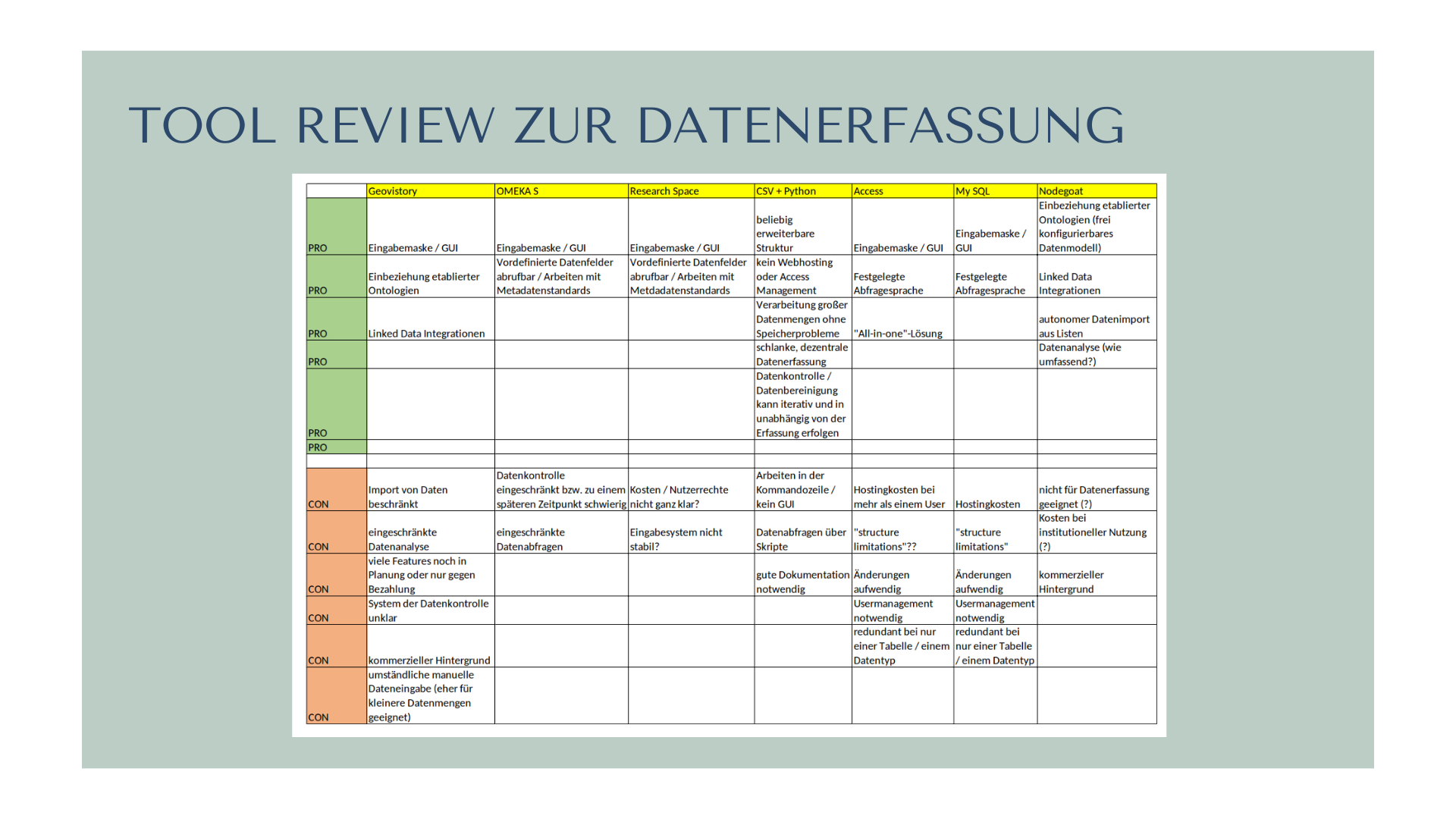
We then decided to view relational or graph databases as an optional end-product rather than the starting point of our research process and decided to experiment with a flexible combination of (versioned) spreadsheets, script-supported data cleaning, and more solid data infrastructures. The DigiKAR geohumanities project analyses spatial relations in Electoral Mainz and Electoral Saxony of the early modern period from two distinct perspectives, which is why we also needed to develop slightly different workflows.
Legal structures of space in work package 2 “Electoral Saxony”
In the Saxony work package, we have decided to approach spaces through their legal capacities, including religious rights, peacekeeping, taxation, or political representation. In this approach, a “mill” is a “mill” because certain legally defined functions within a local community are linked with the place and the people who live and work there. As the Saxony case study focuses on place attributes rather than people’s networks and mainly relies on semi-structured data from historical gazetteers and relatively concise government records, those data are managed via an interface in QGIS that is linked with a relational GIS database on a server hosted by the EHESS Paris. In the case of work package 2, the GIS database is ideal for exploring and enriching the collected place attributes. One long-term goal is to make the interface in QGIS easier to use and to implement a multi-user modus that permits collaborations.
Careers and mobility in work package 3 “Electoral Mainz”
In work package 3, which analyses biographic mobility in Electoral Mainz, the basis for data collection is EXCEL spreadsheets that follow our project-specific factoid model. This event-oriented approach to data is modelled on the factoid approach developed at King’s College London. This means that we gather agency-related events (e.g. “grand tour”) and general life events (e.g. “birth” and “death”) as stated in different sources. Uncertainty or vagueness of the information is captured in a comments column, where we also add important source quotations:
Table design in EXCEL for collecting biographic data
Our dataset provides detailed event information, focusing on who did what when and where. The factoid lists, in which we collected all event-related data, include a unique “factoid_id” for each event. We also categorise the “event_type” according to our project ontologies. We use the columns “event_date”, “event_after_date”, and “event_before_date” to record both exact dates and fuzzy timeframes. The date columns “event_start” and “event_end” contain specific start and end dates to delineate event durations.
Furthermore, our factoid lists contain several columns dedicated to details about persons, locations, and institutions. Noteworthy among these are columns like “person_id”, which serves as a numeric identifier to differentiate individuals within our dataset. The column “person_name” displays standardized names of individuals which we use as labels in data visualization. The columns “person_title” and “person_function” capture academic, noble, or religious titles held by individuals and the functions they perform. We also utilize the “related_persons” column to track relationships, e.g. between children and parents and between students and tutors. While our factoid lists contain some “person_alternative_names” for individuals, a comprehensive list of name variants is stored separately for future reference and research.
The “place_name” column describes the location where events occur and support our spatial analysis, while the “institution_name” column identifies the institutions associated with events and/or agents. Regarding location data, we opted not to differentiate places below the settlement level, nor did we distinguish between ecclesiastical and secular territories. Instead, we associated attributes such as religious affiliation with the functions of person or the institutions they represented. Geocoding of place names was conducted post-normalisation and post-disambiguation, which was necessary due to the the prevalence of old spelling and Latin variants.
Finally, our factoid lists include several columns dedicated to source information. The “event_source” column identifies the sources from which event information is drawn, while the “event_source_quotation” column provides direct quotes from sources. The extensive source columns preserve contextual information that may not be immediately relevant to our visualisation interests but could inspire future research.
Since spring 2023, the focus in our Mainz work package has been cleaning and consolidating the hitherto collected data with Open Refine and Python Scripts. To normalise the entities as far as possible while respecting uncertainty and historical development, we have decided to work with ontology tables that non-hierarchically list the vocabulary we use. For an overview of named entities in the Mainz work package and our data mapping, cf. the ontology lists. Classifications and evaluations of the entities are not included in the data but are flexibly added via vocabulary mappings based on specific research questions. Examples can be found in the Data Categorisation directory.
Separate collection of person names and place names
In order to keep the factoid model and manageable for manual data collection, we have collected general information on persons and places in two separate lists which we could curate indepently from the analytical lenses and use for data disambiguation and normalisation. The separate table of persons contains name variants and final IDs assigned after disambiguation. Similarly, places list contains place names with additional attributes such as place name variants, related territories and coordinates. Please check the DigiKAR wiki of AP3 column names for details.
Analytical lenses in the “Electoral Mainz” work package
To get a better idea of the different types of ecclesiastical, academic, and political agents active in Electoral Mainz between the 16th and 18th centuries, our historians have manually collected biographic data relating to the Mainz government in the Eastern German exclave of Erfurt, Mainz officials represented at imperial institutions such as Reichstag (Imperial Diet), Reichshofrat and Reichskammergericht, and the organisation of the electoral court in Mainz itself. In addition, we have used XML data (harvested via API) and OCR technology to semi-automatically gather information on professors and students active at the early modern university of Mainz.
The following dropdown menu give an overview of the data structure in each of these lenses and indicate the latest updates prior to our automated data consolidation:
“Erfurt” data (collection completed by 2022-11-11, last updated on February 2nd, 2023)
5987 rows of data! Not all persons in this data set have been documented!
| Original Column Name | Mapped Column Name |
|---|---|
| factoid_ID | |
| IsSubject | |
| Reise (sic!) | |
| pers_ID | |
| pers_name | |
| alternative_names | |
| event_after-date | |
| event_before-date | |
| event_start | |
| event_end | |
| event_date | |
| pers_title | |
| pers_function | |
| place_name | |
| inst_name | |
| rel_pers | |
| source_quotations | |
| additional_info | |
| commentsource | |
| source_site | |
| info_dump | |
| Weitere Belegstellen | |
| StaatskalenderID | |
| Import-ID |
“Jahns” data (2023-02-22, last updated February 22nd, 2023)
2081 rows of data!
| Original Column Name | Mapped Column Name |
|---|---|
| factoid_ID | |
| pers_ID | |
| pers_name | |
| alternative_names | |
| event_type | |
| pers_function | |
| place_name | |
| inst_name | |
| rel_pers | |
| source_quotations | |
| additional_info | |
| comment | |
| info_dump | |
| source | |
| source_site |
This spreadsheet has an additional tab with REL_PERS information to be included in final person list. However, this list still needs to be completed.
1756er Staatskalender META FINAL (last updated January 27th, 2023)M
This spreadsheet contains five tabs of biographic data. The “inst_name” column is erroneously named “H” in some tabs. This has been changed in the copy for data consolidation.
| Original Column Name | Mapped Column Name |
|---|---|
| factoid_ID | |
| pers_ID | |
| alternative_names | |
| event_start | |
| pers_title | |
| pers_function | |
| place_name | |
| inst_name | |
| source | |
| pers_name_org | |
| pers_name | |
| source_quotations | |
| comment | |
| source_site | |
| Hilfsspalte | (not in original data model!) |
| additional_info | (not in original data model!) |
| Recherchehinweise | (not in original data model!) |
| ID_Factoid-List | (not in original data model!) |
Overview of the individual tabs in the Staatskalender spreadsheet:
- FS0 = 4457 entries
- FS1 = 4910 entries
- FS2 = 5051 entries
- FS3 = 6602 entries
- FS4 = 6540 entries
Due to the large number of data rows per sheet and the redundant nature of the entries (functions enumerated per year), a vertical consolidation should be performed before a horizontal mapping of entities.
Important information to add to consolidated Staatskalender files:
- add exact name of data source
- add missing person IDs (based on all existing person data)
- carefully analyse cases where middle names might be missing (issue of person disambiguation)
- watch out for entities that are currently NOT captured in the ontology lists (links below)
The 1755 Staatskalender data will not be used in the current project phase.
Professors’ and students’ biographies based on Gutenberg API and Universitätsmatrikel (OCR)
The archival transcripts of the Mainz university registers (“Universitätsmatrikeln”) written with typewriter in the 20th century are easier to read with OCR technology, and mis-interpretations of German special characters (“Umlaute”) can be cleaned automatically. This is why we have decided to work on them first. After reading the PDF files provided by the archive to .txt format, we have performed some basic pre-processing to correct OCR errors and to introduce the #NAME and #SOURCE delimiters to separate person name and source citations (at the end of each entry) from the biographic information given. The biographic information is mostly structured with semi-colons between events, which we can thus read as individual items of a list with Python. Moreover, the transcripts of the university registers contain hints to people that might be identical with others, using
„ein …“„—ein“„—Ein“„. Ein“or„. ein“
to denote this additional information. Reading the registers with Python, the #IDENTITY separator is thus needed as well.
All scripts I have used to split .txt files by several delimiters (including sequences of uppercase letters) have been published in the DigiKAR Github repository. The data structure matches the initially defined model. API and OCR data combined, there are 9013 rows of entries. After the reconstruction of additional events, 2412 rows were added. This combined data frame has 11428 entries. The merging of duplicate events reduces that number to 9323.